4.4. Localization#
![]()
We introduce three variations of Bayes filtering to solve the robot localization problem: Markov localization, Monte Carlo localization, and Kalman filtering.

Localization is the process of estimating the robot’s position using sensor data and the history of executed actions. In this chapter, the robot’s position at time \(k\) is denoted by \(x_k\), so the localization problem is to estimate \(x_k\) at each time instant using the robot’s history of sensor observations, \(z_1, \dots z_k\), and commanded actions \(u_1, \dots , u_{k-1}\).
As we have seen in Chapter 3, when we are able to exploit the Markov property, we need not consider the entire sensor and action history at each time \(k\); instead, we can iteratively compute a probability distribution for the state \(x_k\) using only our belief about the state \(x_{k-1}\), the action \(u_{k-1}\), and the sensor observation \(z_k\). This kind of iterative, online updating is referred to as filtering. The input to the filter is the belief at time \(k-1\), the action \(u_{k-1}\), and the observation \(z_k\). The output of the filter is the new belief, a probability distribution for \(x_k\). Note that when taking this approach we abandon computing the full joint distribution \(P(X_1, \dots X_k)\), and content ourselves to compute only the conditional distribution for \(X_k\) at time \(k\). In this chapter, the filters that we develop will be derived from Bayes’ theorem, and the result is known as Bayes filtering.
We begin the section with a general introduction to Bayes filters, and then develop three specific algorithms, Markov localization, Monte Carlo localization, and Kalman filtering. These three algorithms reflect trade-offs in computational complexity versus accuracy and expressive power. In particular, Markov localization relies on a grid-based representation that can require significant computer memory as well as significant computation in the update process. Monte Carlo localization addresses each of these concerns by using a sampling-based approach, at the expense of accuracy. Kalman filters, on the other hand, provide an exact and optimal solution to the localization problem, but only in the special case when the robot can be described as a linear system and all uncertainties in motion and observation are Gaussian in nature.
4.4.1. A Running Example#
When introducing concepts related to localization, it will be useful to have a short, ground truth trajectory for the robot that we can use to assess the quality of solutions. For this purpose, consider a trajectory that starts at the bottom left of the map, moves to the right, then up between the middle two shelves. We implement this in code in Figure 1.
#| caption: Defining the example truth trajectory.
#| label: fig:defining-ground-truth
left = [(10+i*5,6) for i in range(9)]
up = [(50,6+i*5) for i in range(1,6)]
N = len(left) + len(up)
indices = range(1, N+1)
x = {k:gtsam.symbol('x',k) for k in indices}
values = gtsam.VectorValues()
for i, state in enumerate(left+up): values.insert(x[i+1], state)
values
| Variable | value |
|---|---|
| x1 | 10 6 |
| x2 | 15 6 |
| x3 | 20 6 |
| x4 | 25 6 |
| x5 | 30 6 |
| x6 | 35 6 |
| x7 | 40 6 |
| x8 | 45 6 |
| x9 | 50 6 |
| x10 | 50 11 |
| x11 | 50 16 |
| x12 | 50 21 |
| x13 | 50 26 |
| x14 | 50 31 |
Note above we used a VectorValues to store the ground truth trajectory, which will come in handy again when we simulate the measurements. In Figure 2 we show this ground truth trajectory overlaid on the warehouse map we introduced before.
#| caption: Ground truth trajectory displayed on the base map.
#| label: fig:logistics-ground-truth
ground_truth = np.array([values.at(x[k]) for k in indices])
logistics.show_map(logistics.base_map, ground_truth)
4.4.2. The Bayes Filter#
The Bayes filter is an iterative, one-step sum-product algorithm.
The Bayes filter estimates the state of the robot at the current time (denoted by index \(k\) in our discrete-time representation), given all the measurements and action history up to and including the current time. To simplify notation, we define \(\mathcal{Z}^{k}=\{z_{1},z_{2},\ldots z_{k}\}\), i.e., all measurements up to and including stage \(k\). Similarly, we define the controls \(\mathcal{U}^{k}=\{u_{1},u_{2},\ldots u_{k-1}\}\). Note there is always one less control variable than there are measurements. The Bayes filter computes the conditional probability distribution \(P(X_k | \mathcal{Z}^{k},\mathcal{U}^{k})\), which is also called the filtering distribution.
Assuming that we are given a prior distribution for the initial state of the robot, \(P(X_1)\), we can initialize the Bayes filter for time \(k=1\) by using the sensor observation \(z_1\). Note that no action has yet been applied. Thus, we have
Given this, recursively assuming that we have a probability distribution \(P(X_{k-1}|\mathcal{Z}^{k-1},\mathcal{U}^{k-1})\) over the previous state \(X_{k-1}\), we proceed in two phases:
In the prediction phase we calculate a predictive distribution \(P(X_{k}|\mathcal{Z}^{k-1},\mathcal{U}^{k})\) on the current state \(X_{k}\) given a control \(u_{k-1}\). This is done by marginalizing out the previous state \(X_{k-1}\), by summing over all possible values \(x_{k-1}\) for \(X_{k-1}\): $\( P(X_{k}|\mathcal{Z}^{k-1},\mathcal{U}^{k})=\sum_{x_{k-1}}P(X_{k}|x_{k-1},u_{k-1})P(x_{k-1}|\mathcal{Z}^{k-1},\mathcal{U}^{k-1}). \)$
In the measurement phase we upgrade this predictive density to the filtering distribution \(P(X_{k}|\mathcal{Z}^{k},\mathcal{U}^{k})\) via Bayes’ theorem, given the measurement \(z_{k}\): $\( P(X_{k}| \mathcal{Z}^{k},\mathcal{U}^{k}) \propto L(X_{k};z_{k})P(X_{k}|\mathcal{Z}^{k-1},\mathcal{U}^{k}). \)$
A keen observer will see that step 1 and step 2 above implement one step of the sum-product algorithm from Section 3.4, where in this case the previous state \(X_{k-1}\) is eliminated. Step 1 is a sum, and step 2 is a product. Also, note that while in this chapter we introduced a continuous state, the above is still stated using a sum (\(\sum\)) rather than an integration (\(\int\)). We will switch to continuous integration when we discuss the Kalman filter.
4.4.3. Markov Localization#
Markov localization represents the filtering distribution at each time \(k\) using a discrete grid.
In principle, for a robot that translates in the plane, we take \(x_k \in \mathbb{R}^2\), and the belief associated to the state would be represented by a probability density function. With Markov localization we approximate this continuous representation by using a discrete grid to represent the workspace and assigning finite probability to each cell in the grid. In particular, we assume a finite element discretization such that a density \(p(x_k)\) over continuous states \(x_k\) is approximated by a discrete probability distribution \(P(X_k)\). The only difference from the previous chapter, which also discussed discrete state spaces, is that in a finite element discretization the cardinality of the discrete states is typically much larger. Recall from section 4.1 that for our \(100m \times 50m\) warehouse example, even at a relatively course resolution of 1m by 1m cells, our state space had a cardinality of 5000 finite elements. This makes reasoning over multiple time steps computationally challenging.
By using this finite element discretization we can apply the Bayes filter, as is, on the discrete grid. When applied to robot localization, because we are using a discrete Markov chain representation, this approach has been called Markov Localization.
4.4.3.1. A 1D Example#

Figure 3 illustrates the measurement phase for a simple 1D example. In this environment there are two doors, and the robot has a door sensor. The predictive distribution \(P(X)\) encodes the belief that the robot is near the left door. The likelihood \(L(X;z)\), where measurement (or observation) \(z\) indicates that the robot did perceive a door, models the fact that the robot is more likely to be near a door given \(Z=z\), but also allows for the fact that the door sensor could misfire at any location. Note that the likelihood is un-normalized and there is no need for it to sum to 1. Finally, the posterior \(P(X|z)\) is obtained, via Bayes’ rule, as the product of the prediction \(P(X)\) and the likelihood \(L(X;z)\), and is shown at the bottom as a normalized probability distribution. As you can see, the most probable explanation for the robot state is \(X=5\), but there is a second mode at \(X=17\) due to the bimodal nature of the likelihood. However, that second mode is less probable because of the prior belief over \(X\).
4.4.3.2. Warehouse Example#
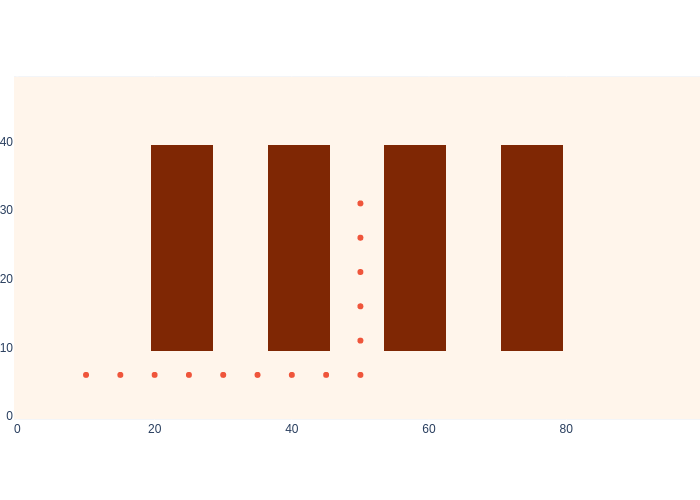
Let us apply Markov localization to the warehouse example, using just the proximity sensor for now. We start by initializing the finite element density representation with a Gaussian prior, centered around the ground truth location for \(k=1\), but with a relatively large standard deviation of 5 meters. We show this in Figure 4.
#| caption: Prior distribution over the robot's initial position.
#| label: fig:logistics-prior
prior_mean = values.at(x[1])
prior_cov = np.diag([25,25])
prior = logistics.gaussian(logistics.map_coords, prior_mean, prior_cov)
logistics.show_map(prior/np.max(prior)+0.1*logistics.base_map)
With respect to implementation, the hardest and most computationally demanding part of the Markov localization algorithm is the prediction step. Recall the formula:
Hence, for every cell in the predictive distribution grid, we need to sum over all cells in the previous grid. Not only that, but for every one of these \(5000^2\), i.e., 25 million cell combinations \((X_k,x_{k-1})\) we need to evaluate the Gaussian motion model \(P(X_{k}|x_{k-1},u_{k-1})\). With python for-loops, this will be rather expensive, so in the code below we build in two speed-ups:
We make the outer loop over the previous grid, and threshold on the probability value (i.e., if the probability value is less than a threshold, we set the value to zero in the output distribution);
We make use of the fact that the
logistics.gaussianfunction is vectorized, i.e., we can process an entire row of the predictive grid at a time.
The fast code can be found in Figure 5.
#| caption: Code for the Markov Localization prediction step.
#| label: code:fast-prediction
def prediction_step(previous, control, motion_model_sigma):
"""Calculate predictive density given control and control stddev."""
cov = np.eye(2) * motion_model_sigma**2
predictive_density = np.zeros((50,100))
for i in range(50):
for j in range(100):
# Speedup 1: threshold on previous[i,j]
if previous[i,j]>1e-5:
previous_xy = logistics.map_coords[i,j]
mean = previous_xy + control
for k in range(50):
# Speedup 1: vectorize Gaussian evaluation over predictive row:
motion_model = logistics.gaussian(logistics.map_coords[k], mean, cov)
predictive_density[k] += motion_model * previous[i,j]
return predictive_density/np.sum(predictive_density)
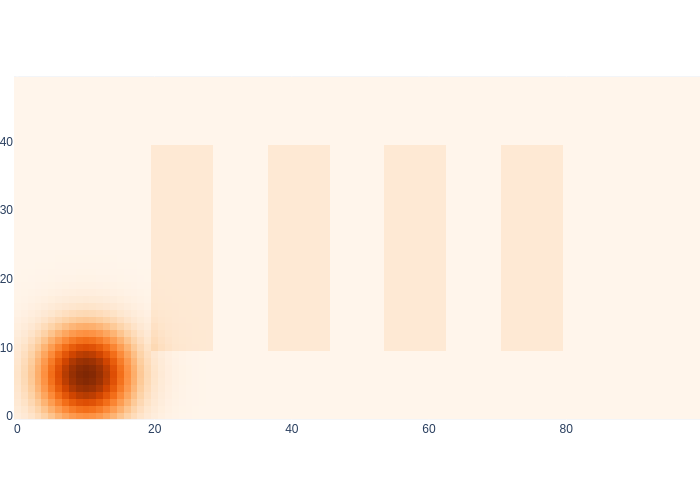
If we have no measurements at all, but have a perfect measurement model, our “control tape” just pushes the Gaussian density along, using the finite element discretization. We illustrate this in Figure 6, which shows the predictive density after taking all 14 actions.
#| caption: Predictive density after taking 14 actions.
#| label: fig:logistics-predictive
motion_model_sigma = 2
current_density = prior
for k in indices[:-1]:
# prediction phase
control = values.at(x[k+1]) - values.at(x[k]) # ground truth control
current_density = prediction_step(current_density, control, motion_model_sigma)
logistics.show_map(current_density/np.max(current_density) + 0.1*logistics.base_map)

The animation in Figure 7 shows the result of this purely predictive reasoning over time.
As you can see, the density grows without bound, and also goes inside the shelves. Without any measurements, if we do not explicitly incorporate knowledge about the world (e.g., a map of obstacles), the robot cannot rule out such situations.
The measurement update step takes the predictive density \(P(X_{k}|\mathcal{Z}^{k-1},\mathcal{U}^{k})\) and upgrades it to the posterior density:
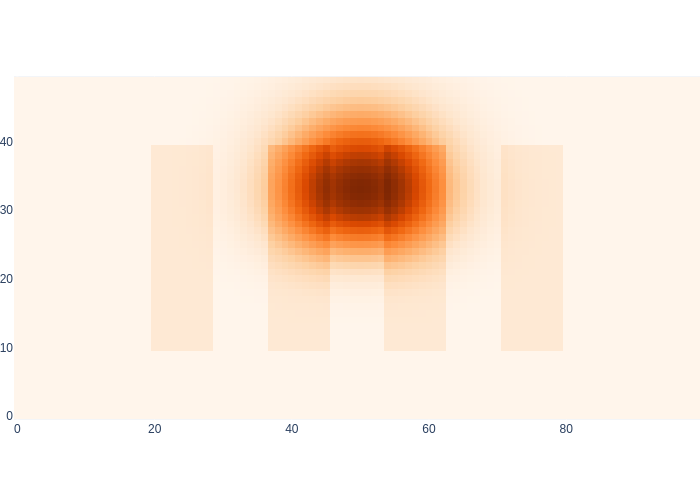
Note that this is so much simpler! We just have to code a pointwise multiplication and we are done. Because the ground truth trajectory never comes near any of the shelves, the proximity sensor is always OFF, and hence we multiply the predictive density with the corresponding proximity_map_off likelihood image, in Figure 8.
#| caption: Posterior density after taking 14 actions.
#| label: fig:logistics-posterior
predictive_density = prior
posterior_density = predictive_density * logistics.proximity_map_off
posterior_density /= np.sum(posterior_density)
for k in indices[:-1]:
# prediction phase
control = values.at(x[k+1]) - values.at(x[k]) # ground truth control
predictive_density = prediction_step(posterior_density, control, motion_model_sigma)
# measurement update phase
posterior_density = predictive_density * logistics.proximity_map_off
posterior_density /= np.sum(posterior_density)
logistics.show_map(posterior_density/np.max(posterior_density) + 0.1*logistics.base_map)
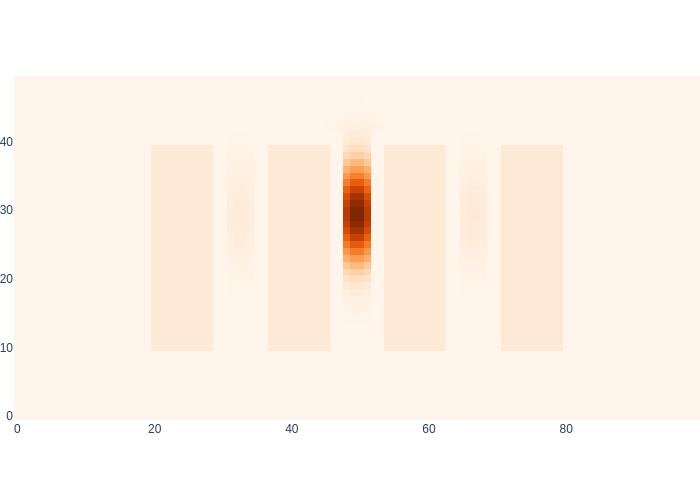

Figure 9 shows Markov localization in action!
The measurement information has squeezed the predictive density to a posterior that fuses predictive information with the knowledge (from the proximity sensor) that the robot cannot be anywhere near the shelves, or the wall. Note that the density is still spreading in the direction that the sensor does not yield information.
4.4.3.3. Exercises#
In principle our motion model should have told us that we cannot move inside shelves. How would you change the prediction code to make this so?
The full Markov localization algorithm takes less time than the code without the measurement update. We do more work yet have faster inference. Why?
4.4.4. Monte Carlo Localization#
Localization with a particle filter is known as Monte Carlo Localization.
The above finite element discretization of space is very costly, and most of the memory and computation is used to compute near-zero probabilities. While there are ways to deal with this, switching to a sampling-based representation gets us more bang for the buck computation-wise. And, as we will see, it also leads to a very simple algorithm. The sampling-based implementation of a Bayes filter is known as a particle filter. Below we discuss it in a 2D context, but it is in fact rather general. When used for robot localization, this technique is known as Monte Carlo Localization or MCL [Dellaert et al., 1999].
A particle filter approximates the Bayes filter by (a) replacing an explicit probability distribution by a set of samples, and (b) approximating the prediction step in the Bayes filter with a Monte Carlo approximation. We recursively assume that we have access to a sampling based approximation of the filtering density over the previous state \(x_{k-1}\), as a set of \(S\) weighted samples:
in which \(x_{k-1}^{(s)}\) is the \(s^{th}\) sample, and \(w_{k-1}^{(s)}\) is its weight.
We then implement the process in two steps, called the prediction and update steps.:
In the prediction step we approximate the predictive distribution \(p(x_{k}|\mathcal{Z}^{k-1},\mathcal{U}^{k})\) by drawing \(S\) unweighted samples from the following mixture density of motion model densities: \begin{equation} { x_k^{(t)} }{t = 1 \dots S} \sim \sum_s w{k-1}^{(s)} P(x_{k}|x_{k-1}^{(s)},u_{k-1})P(x_{k-1}^{(s)}|\mathcal{Z}^{k-1},\mathcal{U}^{k-1}). \end{equation}
In the update step, the measurement is used to convert this predictive density to a weighted sample approximation of the filtering distribution, by weighting each unweighted sample with the likelihood of \(x_k^{(t)}\) given the measurement \(z_{k}\): \begin{equation} p(X_{k}|\mathcal{Z}^{k},\mathcal{U}^{k}) \approx {(x_k^{(t)}, L(x_k^{(t)};z_{k}))}{t = 1 \dots S}. \end{equation} We initialize the algorithm with a set of \(S\) samples from the prior, weighted by the likelihood on the first \(x_1\) given the first measurement \(z_1\): \begin{equation} P(X_1|\mathcal{Z}^1={z_1}, \mathcal{U}^1={}) \approx {(x_1^{(t)}, L(x_1^{(t)};z_1))}{t = 1 \dots S}~\text{with}~x_1^{(t)}\sim p(X_1) \end{equation} In the “vanilla” particle filter outlined above, the number of samples stays constant over time, but variants exist that adapt the number of samples to the complexity of the density over time, or even to the available computation. Used in that way, a particle filter can be used as a “just in time” algorithm.
We will now describe the prediction and update steps in more detail, and illustrate the algorithm using our warehouse scenario.
4.4.4.1. The Prediction Step#
The prediction phase is the more complex of the two steps. To illustrate how it works, we will us a simple example in which we represent a Gaussian mixture density by a set of weighted particles. A mixture density is simply a weighted sum of component densities, in this case a set of motion models. The weights define a probability mass function over the component indices and hence should sum to 1. Sampling from a mixture density proceeds in two steps:
Pick a component according to the weight distribution.
Sample from the component.
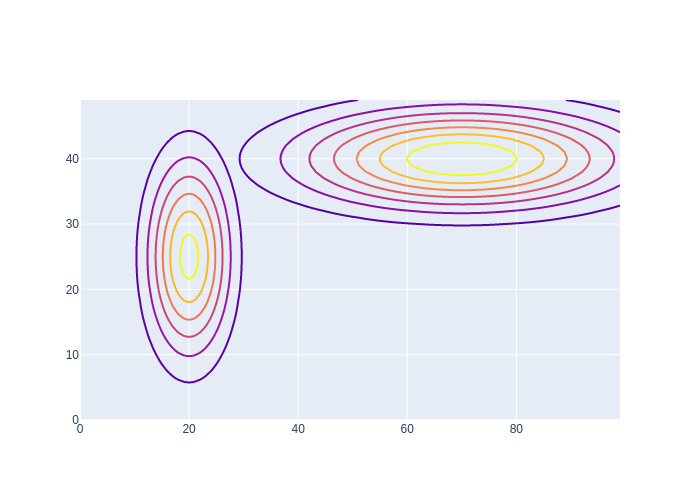
#| caption: Two Gaussian distributions that combine into a mixture density.
#| label: fig:logistics-mixture
means = [gtsam.Point2(x,y) for x,y in [(20,25),(70,40)]]
covariances = [np.diag([sx**2,sy**2]) for sx,sy in [(5,10),(20,5)]]
data = [go.Contour(z=logistics.gaussian(logistics.map_coords, mean, cov), contours_coloring='lines',
line_width=2, showscale=False) for mean,cov in zip(means,covariances)]
fig = go.Figure(data=data); fig.show()
#| caption: Samples from a mixture of two Gaussian distributions.
#| label: fig:logistics-samples
component_indices = rng.choice(2, size=1000, p=[0.9,0.1])
samples = np.array([rng.multivariate_normal(means[s], covariances[s]) for s in component_indices])
fig.add_trace(go.Scatter(x=samples[:,0],y=samples[:,1], mode="markers",
marker=dict(size=3, color="red")))
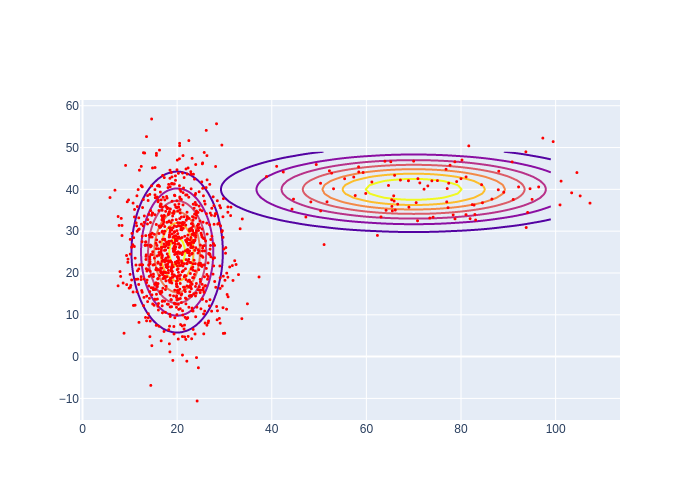
As a toy example, let us assume a Gaussian mixture density with just two Gaussian components, with weights 0.9 and 0.1, respectively, and coded up in Figure 10. The code in Figure 11 generates 100 samples, rather inefficiently. As you can see the first component is chosen much more often, which is exactly what we expect. Armed with this insight about sampling mixtures, we apply it below to code up the MCL prediction step:
def predict_samples(samples, weights, control, motion_model_sigma, size=500):
"""Create predictive density from weighted samples given control and control stddev."""
weights /= np.sum(weights)
component_indices = rng.choice(len(samples), size=size, p=weights)
means = samples + control
cov = np.eye(2) * motion_model_sigma**2
return np.array([rng.multivariate_normal(means[s], cov) for s in component_indices])
4.4.4.2. Evaluating the Likelihood in the Update Step#
As before, we know that the ground truth trajectory stays away from obstacles at all times. However, we only have access to a likelihood image, not a function that evaluates the likelihood for an arbitrary coordinate. The following function calculates the correct cell for looking up the likelihood, and returns 0 likelihood if out of bounds:
def likelihood_off(xy):
"""Calculate likelihood by looking up value in proximity_map_off."""
j, i = np.round(xy).astype(int)
if i<0 or i>49 or j<0 or j>99: return 0.0
return float(logistics.proximity_map_off[i,j])
4.4.4.3. MCL Warehouse Example#
Now that we know how to do the prediction step and evaluate the likelihood function, we are able to implement the entire Monte Carlo localization method. First, let us obtain 500 samples from the prior, as shown in Figure 12.
#| caption: 500 samples from the prior density at the start.
#| label: fig:logistics-prior-samples
S=500
prior_samples = rng.multivariate_normal(prior_mean, prior_cov, size=S)
logistics.show_map(0.1*logistics.base_map, markers=prior_samples,
marker=dict(size=3,color="red"))
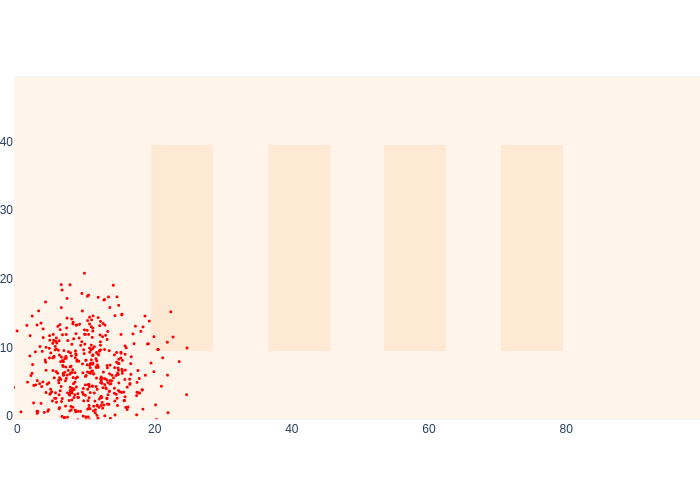
Compare this sampling-based representation with the Markov localization prior above in Figure 4, and note they represent the same density, but using vastly different representations. In fact, they also use vastly different resources: for Markov localization we used 5000 cells, and here we use 500 samples, each represented as a two-dimensional vector. In higher-dimensional state spaces this difference is even greater. What would happen if we wanted to represent orientation as well?
However, as discussed, we start off MCL with a set of weighted samples \(\{(x_1^{(t)}, L(x_1^{(t)};z_1))\}_{t = 1 \dots S}\), which represents the posterior for \(k=1\). We do this by weighting each sample from the prior with the likelihood, in Figure 13.
#| caption: By weighting the samples with the likelihood, we get a representation for the posterior.
#| label: fig:logistics-posterior-samples
samples = prior_samples
weights = np.apply_along_axis(likelihood_off, 1, samples)
logistics.show_map(0.1*logistics.base_map, markers=samples,
marker=dict(color="red", opacity=0.1, size=10*weights/np.max(weights)))
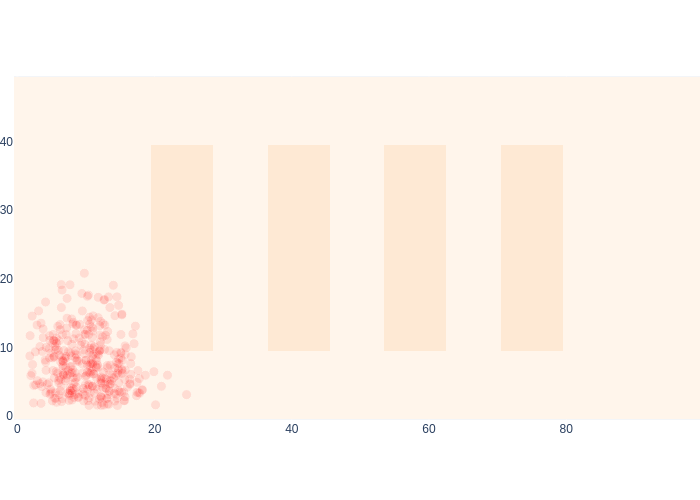
Note that all samples close to the wall and/or the shelves have disappeared, as they have zero weight given the proximity sensor is OFF. All remaining samples have the same weight.
Let us now iterate over all time steps in the code below:
for k in indices[:-1]:
# prediction phase
control = values.at(x[k+1]) - values.at(x[k]) # ground truth control
samples = predict_samples(samples, weights, control, motion_model_sigma)
# measurement update phase
weights = np.apply_along_axis(likelihood_off, 1, samples)
#| caption: Monte Carlo Localization in action!
#| label: fig:mcl_in_action
# logistics.show_map(0.1*logistics.base_map, markers=samples,
# marker=dict(color="red", opacity=0.1, size=10*weights/np.max(weights)))

Figure 15 above shows Monte Carlo localization in action!
#| caption: The final posterior estimate for MCL
#| label: fig:mcl_final
logistics.show_map(0.1*logistics.base_map, markers=samples,
marker=dict(color="red", opacity=0.1, size=10*weights/np.max(weights)))
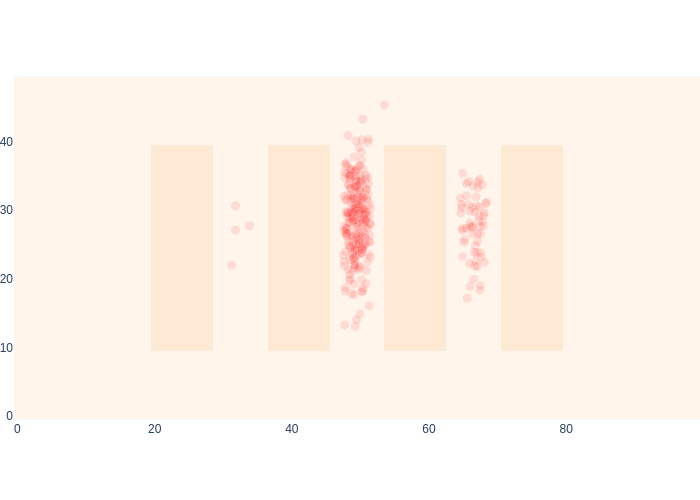
Comparing the final posterior estimate of MCL, in Figure 16 with that of Markov localization in Figure 8, we see that the results are mutually consistent. Not only that, but MCL runs at least an order of magnitude faster.
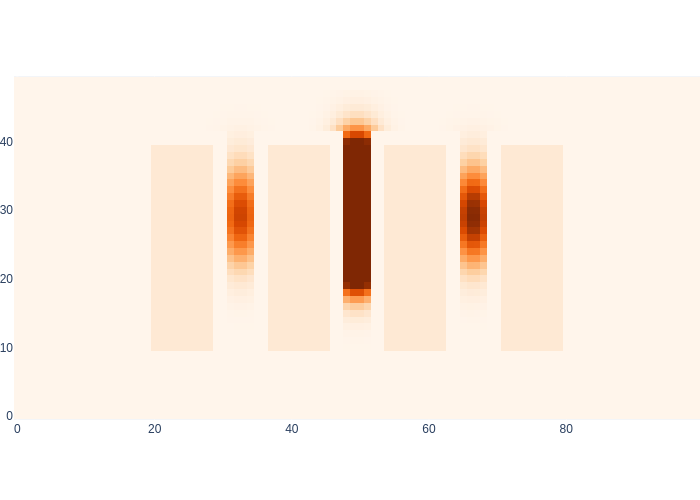
You might wonder about the samples that made it into the seemingly wrong aisles between the shelves. However, if we crank up the Markov localization visualization by a factor of 10, you can see in Figure 17 that in fact the probability of being in those aisles is actually non-zero.
#| caption: Markov Localization visualized with a heatmap.
#| label: fig:logistics-markov-heatmap
logistics.show_map(10*posterior_density/np.max(posterior_density) + 0.1*logistics.base_map)
MCL can be made to be more accurate than Markov localization, since the accuracy of the sample-based approximation can be increased by simply increasing the number of samples. Of course, we can also increase the resolution of the Markov localization representation, but at exponential cost. In contrast, the samples needed are proportional to the “volume” that the density occupies, an observation that underlies adaptive variants of the particle filter.
4.4.4.4. Adding Range Sensing#
Finally, and this is will be rather easy in MCL, let us investigate the effect of adding range sensing. This time we won’t have the luxury to know the entire measurement sequence in advance, as we did with proximity. Rather, the likelihood will have to be given the output of the RFID sensor. Remember that was either a beacon ID and a range \((i,r)\), or \((\text{None},\infty)\).
def likelihood_range(xy, rfid_measurement):
"""Calculate likelihood of xy given range measurement."""
_id, _range = rfid_measurement
if _id is None:
j, i = np.round(xy).astype(int)
if i < 0 or i > 49 or j < 0 or j > 99:
return 0.0
return float(logistics.out_of_bound_map[i, j])
else:
sigma = 1.0 # In meters
range_for_xy = logistics.rfid_range(xy, logistics.beacons[_id])
return 0.0 if range_for_xy is None else np.exp(-1/(2 * sigma**2) * (range_for_xy - _range)**2)
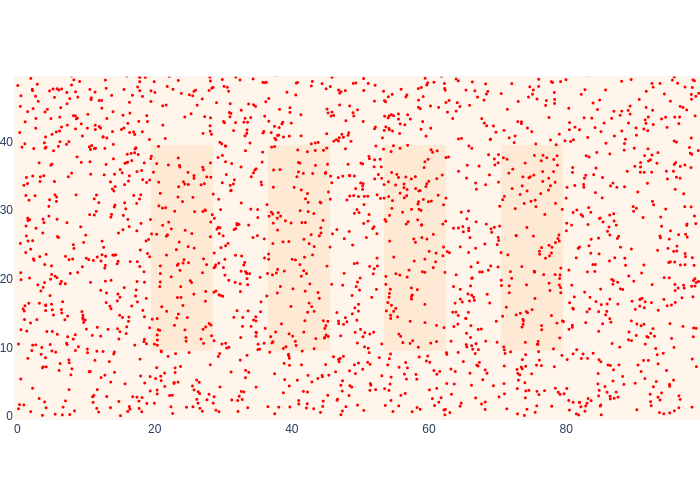
We can also use this to illustrate how to globally localize, without any prior information at all, except that we are somewhere in the warehouse. We can encode this knowledge as samples by uniformly sampling over the entire range for \(x\) and \(y\). This corresponds to assuming that the prior distribution on the initial state is a uniform distribution, sometimes called the uniform prior assumption. Because our knowledge is now so diffuse, we use 2000 samples instead of 500 to better approximate it, shown in Figure 18.
#| caption: 2000 samples from an *uninformative* prior density at the start, i.e., we don't know where we are.
#| label: fig:logistics-uninformative-prior-samples
T=2000
prior_samples = rng.uniform(low=gtsam.Point2(0,0), high=gtsam.Point2(100,50), size=(T,2))
logistics.show_map(0.1*logistics.base_map, markers=prior_samples,
marker=dict(size=3,color="red"))
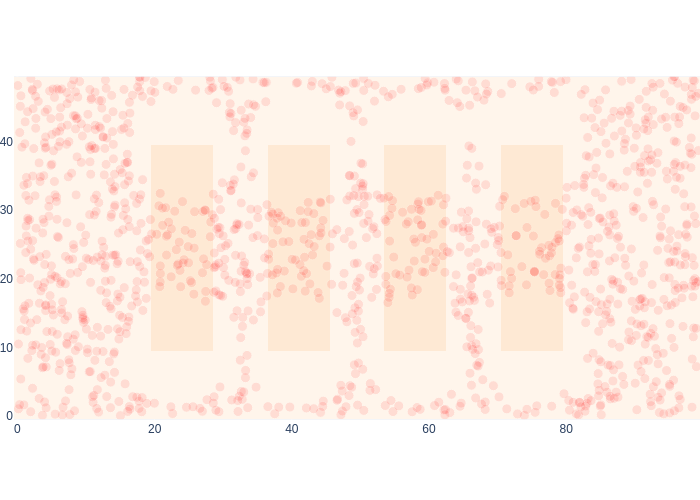
The first range measurement happens to be out of range, and in Figure 19 we can see the effect on our estimate for the posterior \(p(x_1|z_1)\) quite clearly.
#| caption: Sample-based posterior after a single "out of range" measurement.
#| label: fig:logistics-posterior-samples-out-of-range
samples = prior_samples
range_measurement = logistics.rfid_measurement(values.at(x[1]))
weights = np.apply_along_axis(likelihood_range, 1, samples, range_measurement)
logistics.show_map(0.1*logistics.base_map, markers=samples,
marker=dict(color="red", opacity=0.1, size=10*weights/np.max(weights)))
As expected, the likelihood has “punched holes” around the beacons, because we know we cannot have been near them. When we combine this with the proximity OFF measurement, we improve our posterior even more:, as shown in Figure 20.
#| caption: Upgrading the posterior with a single "proximity=OFF" measurement.
#| label: fig:logistics-posterior-samples-proximity-off
weights *= np.apply_along_axis(likelihood_off, 1, samples)
logistics.show_map(0.1*logistics.base_map, markers=samples,
marker=dict(color="red", opacity=0.1, size=10*weights/np.max(weights)))
We are now ready to bring it all together by multiplying two likelihoods in every measurement update phase:
for k in indices[:-1]:
# prediction phase
control = values.at(x[k+1]) - values.at(x[k]) # ground truth control
samples = predict_samples(samples, weights, control, motion_model_sigma)
# measurement update phase
range_measurement = logistics.rfid_measurement(values.at(x[k]))
weights = np.apply_along_axis(
likelihood_range, 1, samples, range_measurement)
weights *= np.apply_along_axis(likelihood_off, 1, samples)

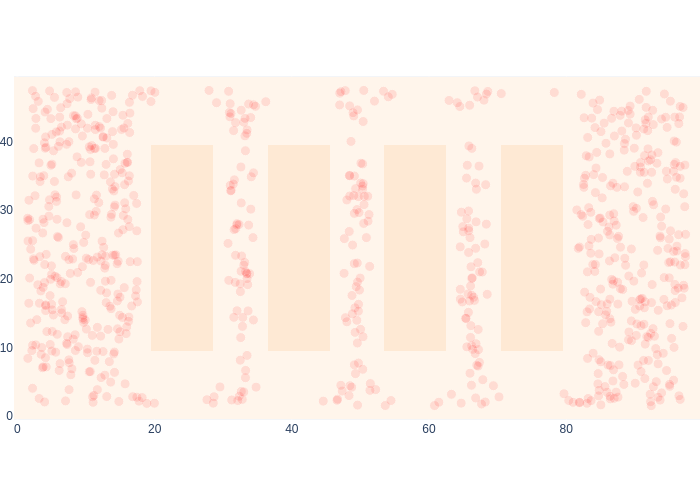
Figure 21 shows global localization in action! At the onset, the robot is very confused as to where it might be in the warehouse, but it still has some knowledge. Then it moves within range of beacon \(0\), which immediately localizes it, acting a bit like a GPS sensor, especially in combination with what was sensed before. After that the particular shape of the range likelihoods makes for some interesting antics. Note that for the last few time steps in the animation we are out of beacon range, and you can see a bit of “squeezing” of the sample cloud at the very top, because of this.
#| caption: Global localization using Monte Carlo Localization.
#| label: fig:logistics-mcl-global-final
logistics.show_map(0.1*logistics.base_map, markers=samples,
marker=dict(color="red", opacity=0.1, size=10*weights/np.max(weights)))
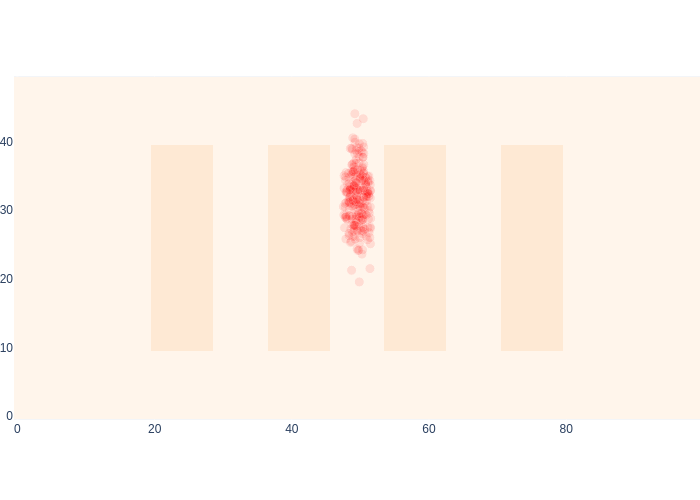
After the final update, shown in Figure 22, we are quite a bit more certain that the robot is in the center aisle.
In summary, this example showed off two nice properties of Monte Carlo localization (and, for that matter, Markov localization):
We can reason about multi-model densities.
We can incorporate missing information/data, such as out of range measurements.
4.4.5. Kalman Smoothing and Filtering#
For linear systems with Gaussian uncertainty, the Kalman filter is both efficient and optimal.
The final and mathematically most challenging approach we will discuss is Kalman smoothing and filtering. Ironically, while the math is more difficult, the circumstances in which these methods can be applied are more limited. The math is only exact for (a) linear measurement and motion models and (b) Gaussian additive noise. In addition, although there are ways to deal with nonlinear models, a more serious limitation is that the density on the state is restricted to Gaussian distributions.
These methods are incredibly important in robotics. In spite of all their limitations, Kalman filters are incredibly efficient, and are at the core of the navigation stack (i.e., the software that handles everything from low-level sensor processing to higher-level localization) of many systems, robots and otherwise. In fact, the Kalman filter was implemented in the sixties on Apollo flight computers, which had extremely limited computational hardware.
4.4.5.1. Factor Graphs and Least Squares#
When given measurements and actions, we can create a factor graph directly.
Kalman smoothing is the equivalent of the Viterbi algorithm for hidden Markov model, but for continuous state spaces.
In the continuous case, we build the factors directly from given control inputs and measurements. A factor graph now encodes the negative log-posterior
In the continuous case we use minimization of the log-likelihood rather than maximization over the probabilities. The main reason is because then inference becomes a linear least-squares problem.
A least-squares problem is convex and can be solved in closed form. The linear terms within the square norm above are sparse, in the sense that \(X_i\) is only a subset of the continuous variables \(X\). For example, a simple sensor fusion problem on two scalar variables \(x_1\) and \(x_2\) would be one where both have a simple prior on them, resp. with \(\mu_1=3\) and \(\mu_2=7\), and we know that the difference between them is equal to \(5\). This yields three factors that have to be minimized over \(x_1\) and \(x_2\):
This corresponds to the following
\(X_i\) |
\(A_i\) |
\(b_i\) |
|---|---|---|
\(x_1\) |
[1] |
3 |
\(x_1, x_2\) |
[-1 1] |
5 |
\(x_2\) |
[1] |
7 |
We can collect all three matrices \(A_1\), \(A_2\), and \(A_3\) into one sparse matrix \(A\) and corresponding right-hand-side \(b\):
You can convince yourself that the minimization problem can then be written as
which is now a sparse linear least-squares problem.
Setting the derivative to zero and solving for \(X^*\) we obtain:
\begin{aligned} A^T(A X^* - b) &= 0 \ (A^T A) X^* &= A^T b \ X^* &= (A^T A)^{-1} A^T b \end{aligned}
This is known as a system of normal equations, and the last equation above is a closed from solution for it.
Solving a linear least-squares problem this way can be expensive. The matrix \(A\) can be very high dimensional, but luckily in many sensor fusion scenarios it is exceedingly sparse. Still, we have to proceed with some care, as in general the matrix \((A^T A)^{-1}\) is not sparse. The matrix \(Q \doteq A^T A\) is known as the Hessian or Information Matrix and has dimensions \(n\times n\) if there are \(n\) scalar unknowns. In general, it takes \(O(n^3)\) work to compute it, which is only 27 for \(n=3\), but is already 1 billion for \(n=1000\).
4.4.5.2. Numerical Example#
This method is trivial to implement in numpy for the small example above:
A,b = np.array([[1.,0.],[-1.,1.],[0.,1.]]), np.array([3.,5.,7.])
X_optimal = np.linalg.inv(A.T @ A) @ A.T @ b
print(X_optimal)
[2.66666667 7.33333333]
Note that in this simple sensor fusion example, a compromise solution is obtained: all factors are equally unhappy. We can compute the error vector as \(A X^* - b\) and find that the errors is equally divided between all factors:
print(A @ X_optimal - b)
[-0.33333333 -0.33333333 0.33333333]
4.4.5.3. Exercise#
What would make the errors not divide equally between factors?
4.4.5.4. Sparse Least Squares#
In practice we use sparse factorization methods to solve for \(X^*\). In particular, sparse Cholesky factorization can efficiently decompose the sparse Hessian \(Q\) into its matrix square root \(R\)
where \(R\) is upper-triangular and sparse as well. There is one wrinkle: the sparsity of \(R\) depends (dramatically) on the column ordering chosen for \(A\), and the optimal ordering is hard to find (NP-complete, in fact). Hence, many heuristic ordering methods exist that are applied in practice.
After we find \(R\), which is where the heavy lifting occurs, we can efficiently solve for \(X^*\) in two steps. First, we solve for an auxiliary vector \(y\): \begin{aligned} (R^T R) X^* &= A^T b \ R^T (R X^*) &= A^T b \ R^T y &= A^T b \end{aligned}
In the last line, \(R^T\) is lower-triangular, and hence \(y\) can be easily solved for proceeding from \(y_1\) to \(y_n\), via forward-substitution. We then turn around and use the computed value of \(y\) to solve for \(X^*\) by back-substitution:
Both of these steps are \(O(n^2)\) for dense matrices, but typically closer to \(O(n)\) for sparse matrices.
There is a deep connection between sparse factorization methods and the sum-product algorithm discussed in the previous chapter. In fact, sparse factorization is sum-product, where one continuous variable is eliminated at a time. The factor graph corresponding to a sparse least-squares problem corresponds to its sparsity pattern. In this graphical framework, the product is implemented by collecting all factors connected to that variable, and the sum is implemented by expressing the variable to be eliminated as a linear combination of its neighbors in the graph.
4.4.5.5. Example with GPS-Like Measurements#
We build a factor graph and then simply call
optimize.
GTSAM is built around state-of-the-art sparse factorization methods, and hence can very efficiently solve large sensor fusion problems like the localization problem with GPS-like measurements. Below we illustrate this with an example in code for the GPS-like measurements, which is easily tackled using optimization. Range measurements can also be handled.
We simulate measurements using the ground truth trajectory, but with noise added, by creating a quick Bayes net do this for us. Remember from the previous section that the measurements are in centimeters, so the number \(30\) below is the standard deviation of the measurement noise, in centimeters:
C = 100 * np.eye(2)
measurement_model_sigma = 30
z = {k: gtsam.symbol('z', k) for k in indices}
bn = gtsam.GaussianBayesNet()
for k in indices:
conditional_on_zk = gtsam.GaussianConditional.FromMeanAndStddev(
z[k], C, x[k], [0, 0], measurement_model_sigma)
bn.push_back(conditional_on_zk)
simulation = bn.sample(values)
print(f"measurement on {values.at(x[1])} = {simulation.at(z[1])}")
measurement on [10. 6.] = [1038.61635761 632.63644323]
Notice how the measurement is scaled by 100, and is corrupted by noise. Now we are finally ready to create a GaussianFactorGraph that will fuse the information from the prior, the measurements, and the motion models. This is done in Figure 23.
#| caption: Creating a Gaussian Factor Graph for Kalman Smoothing.
#| label: fig:Kalman-graph
gfg = gtsam.GaussianFactorGraph()
# The prior
p_x1 = gtsam.GaussianDensity.FromMeanAndStddev(x[1], values.at(x[1]), 0.5)
gfg.push_back(p_x1)
# Create motion model factors from ground truth trajectory displacements
for k in indices[:-1]:
state = values.at(x[k])
next_state = values.at(x[k+1])
displacement = next_state - state
# |next_state - (A*state + B*u)|
gfg.push_back(gtsam.GaussianConditional.FromMeanAndStddev(
x[k+1], np.eye(2), x[k], displacement, motion_model_sigma))
# Convert the conditionals in Bayes net from above into likelihood factors
for k in indices:
conditional_on_zk = bn.at(k-1)
measurement = simulation.at(z[k])
likelihood_on_xk = conditional_on_zk.likelihood(measurement)
gfg.push_back(likelihood_on_xk)
In Figure 24 we show the factor graph, which looks exactly like the one for inference in an HMM, except we now have more states, and they are continuous. The two problems have essentially the same computational structure.
#| caption: The factor graph for a Kalman smoother.
#| label: fig:logistics-factor-graph
position_hints = {'x': 1}
pos = {0:(0.35,1)}
pos.update({k:(k+0.5,1) for k in indices[:-1]}) # binary
pos.update({k+N-1:(k,0.5) for k in indices}) # unary
show(gfg, hints=position_hints, factor_positions=pos)

Now we can find the optimal solution, using the optimize method. In the Gaussian factor graph case, this solves a linear least-squares problem with a continuous variant of the max-product algorithm from Section 3.4:
least_squares_solution = gfg.optimize()
Finally, in Figure 25 we compare the estimated trajectory with the ground truth trajectory.
#| caption: Estimated trajectory using a Kalman smoother.
#| label: fig:logistics-estimated-Kalman
estimated = np.array([least_squares_solution.at(x[k]) for k in indices])
logistics.show_map(logistics.base_map, estimated)
4.4.6. GTSAM 102#
A deeper dive in the GTSAM concepts used above.
Recall the GaussianFactorGraph gfg from Figure 24. We can also visualize the sparse \(A\) matrix, which is called the sparse Jacobian of the system. This is done in Figure 26.
#| caption: The Jacobian matrix $A$ (and RHS $b$) corresponding to the above factor graph
#| label: fig:logistics_proximity_map2
A, b = gfg.jacobian()
px.imshow(np.abs(A), color_continuous_scale='Reds')
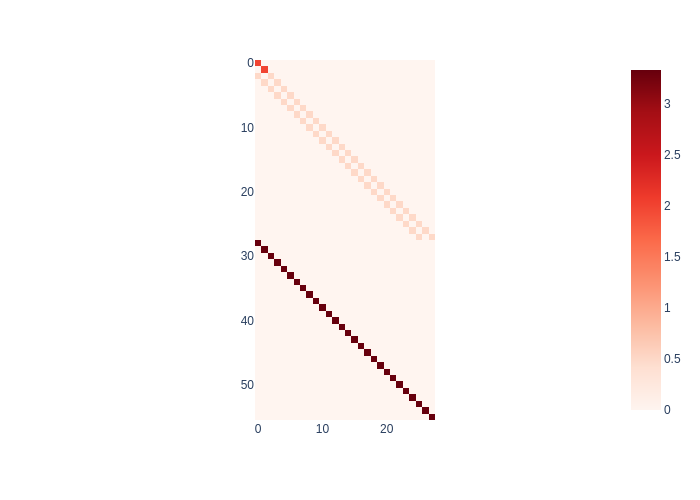
In fact, the deep connection between factor graphs and sparse linear algebra is this:
Columns correspond to variables, and rows correspond to factors.
You can make out, from the top:
the first two rows correspond to the prior
the two darker diagonals correspond to the motion model factors
the single red diagonal corresponds to the measurements
We can use the method eliminateSequential to use the linear-Gaussian sum-product algorithm (matrix factorization!) to turn it into a Bayes net, which encodes the multivariate Gaussian posterior. The result of this transformation is shown in Figure 27.
#| caption: Bayes net representing a multivariate Gaussian posterior.
#| label: fig:bayes-net-gaussian-posterior
gaussian_posterior = gfg.eliminateSequential()
show(gaussian_posterior, hints=position_hints)

This Bayes net is the upper-triangular (DAG!) Cholesky factor \(R\) we discussed above, shown as a sparse matrix in Figure 28.
#| caption: The upper triangular matrix corresponding to the above Bayes net.
#| label: fig:upper-triangular-gaussian-posterior
R, d = gaussian_posterior.matrix()
display(px.imshow(np.abs(R), color_continuous_scale='Reds'))
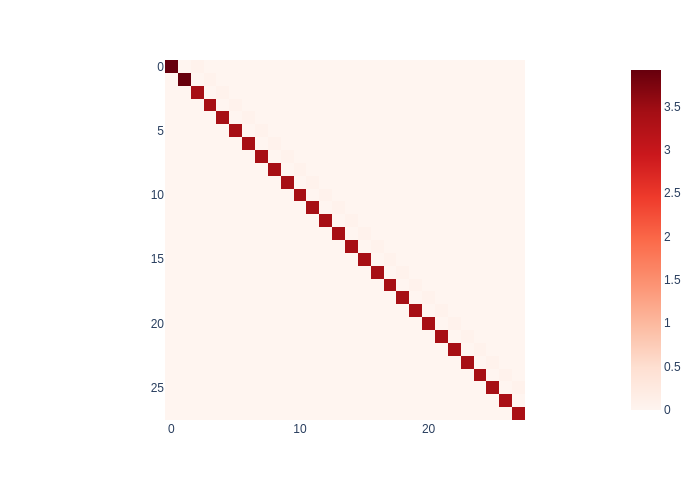
Indeed, here the correspondence is:
Columns correspond to variables, and rows correspond to Gaussian conditionals.
In general, the correspondence is about block columns, as variables in this case are two-dimensional, and block rows. For example, the first GaussianConditional in the gaussian_posterior Bayes net corresponds to the first two rows above, and can be shown like so:
gaussian_posterior.at(0).print("First two rows are: ")
First two rows are: p(x1 | x2)
R = [ 3.91933 0 ]
[ 0 3.91933 ]
S[x2] = [ -0.0637865 0 ]
[ 0 -0.0637865 ]
d = [ 39.3312 24.0585 ]
No noise model